
Вы слышали о стеках и задавались вопросом, что это такое? У вас есть общая идея, но вам интересно, как реализовать стек Python? Вы зашли по адресу!
В этой статье вы узнаете:
- Как узнать, когда стек является хорошим выбором для структуры данных
- Как решить, какая реализация лучше всего подходит для вашей программы
- Какие дополнительные соображения следует учитывать в отношении стеков в многопоточной или многопроцессорной среде
Это руководство предназначено для питонистов, которым удобно запускать скрипты, которые знают, что такое list, как его использовать, и которым интересно, как реализовать стеки в Питоне.
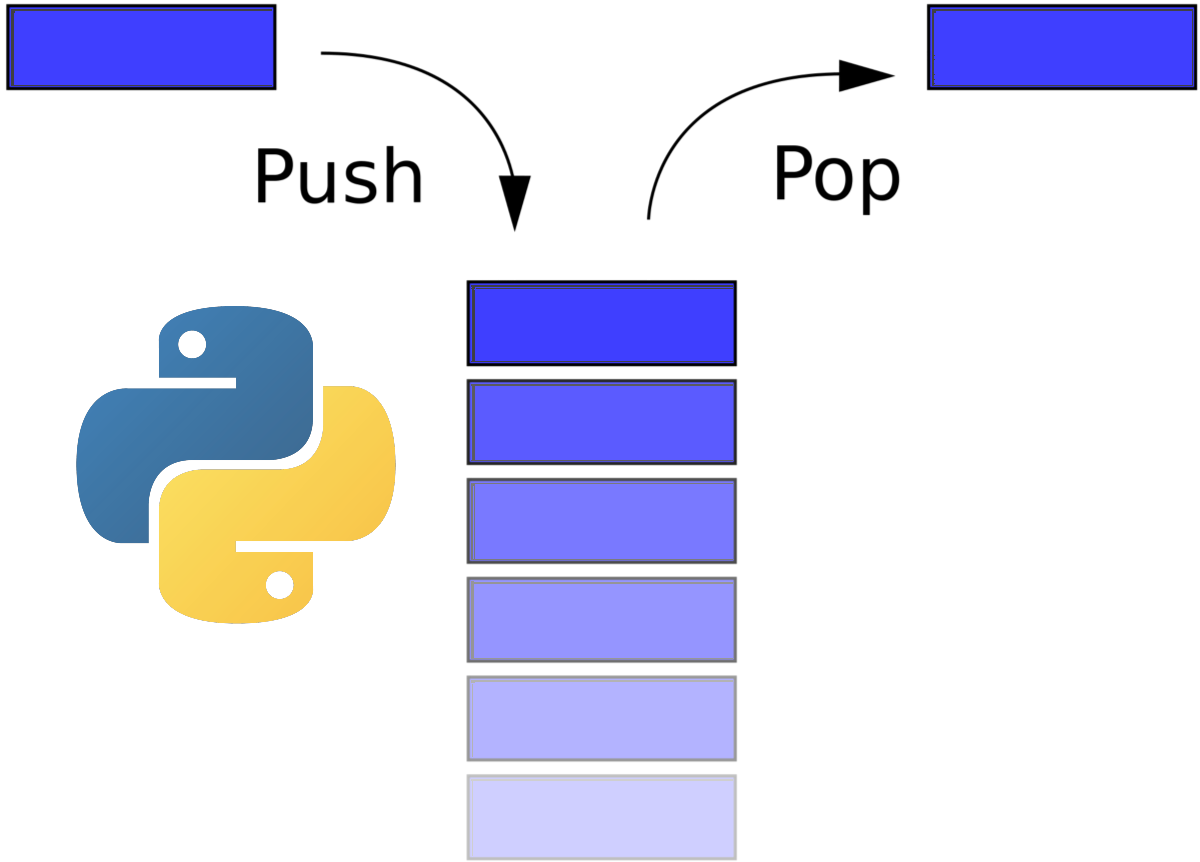
Что такое стек?
Стек – это структура данных, в которой элементы хранятся в порядке Last-In/First-Out (Последним зашел/Первым вышел). Это часто называют LIFO. В отличие от очереди, в которой элементы хранятся в порядке FIFO (Первым зашел/Первым вышел).
Вероятно, проще всего понять стек, если вспомните как работает функция отмены Undo в вашем текстовом редакторе.
Давайте представим, что вы редактируете файл Python, как пример. Сначала вы пишите новую функцию. Это действие добавляет новый элемент в стек отмены операций:
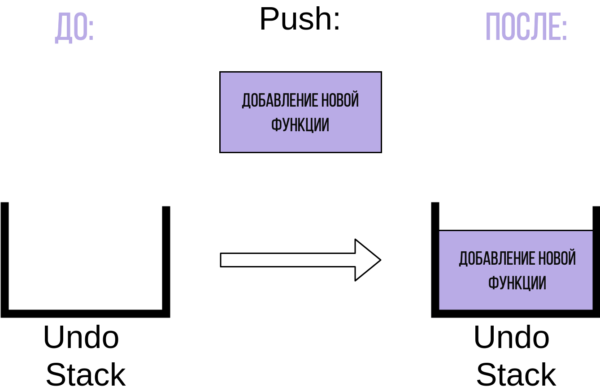
В стеке теперь есть операция добавления функции. После добавления функции вы удаляете слово из комментария. Это действие также добавляется в стек отмены операций:
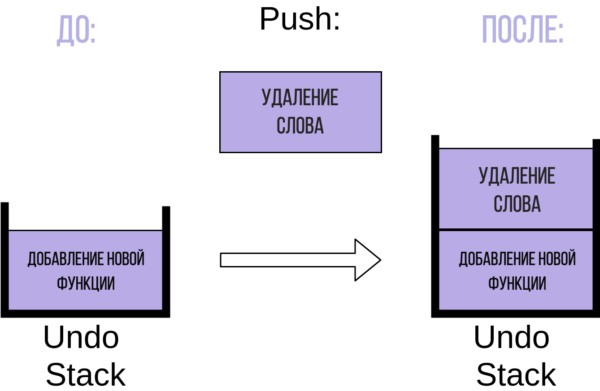
Обратите внимание, как элемент “Удаление слова” помещается в вершину стека.
Далее в редакторе вы делаете отступ в комментарии, чтобы он был правильно выровнен:
Далее в редакторе вы делаете отступ в комментарии, чтобы он был правильно выровнен:
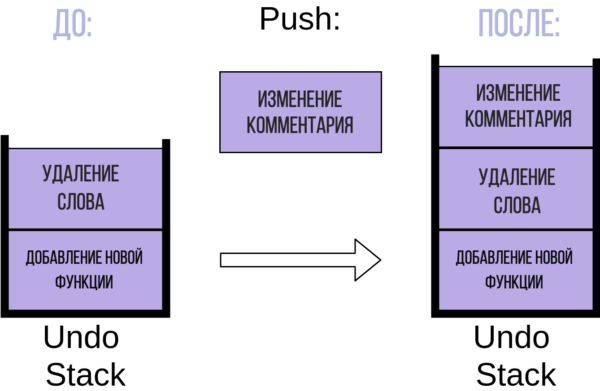
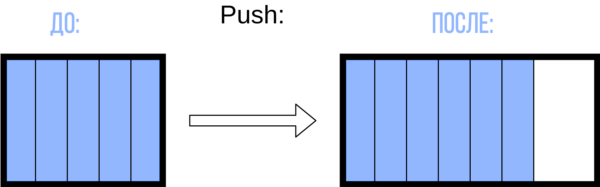
Каждая из этих команд хранится в стеке отмены операций, причем каждая новая команда помещается на вершину стека. Операция добавление новых элементов в стек называется push.
Теперь вы решили отменить все три операции, поэтому нажимаете команду отменить. Это действие забирает элемент из вершины стека (в данном примере операцию “Изменение комментария”) и удаляет его:
Теперь вы решили отменить все три операции, поэтому нажимаете команду отменить. Это действие забирает элемент из вершины стека (в данном примере операцию “Изменение комментария”) и удаляет его:
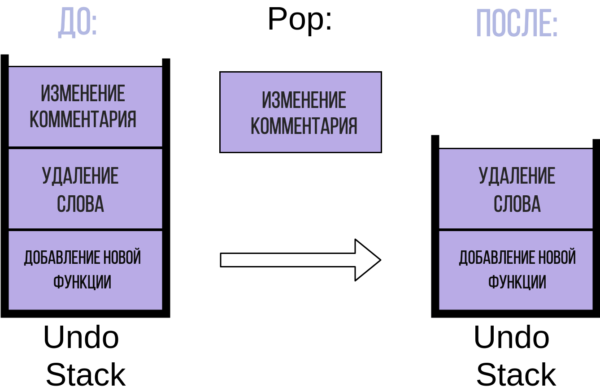
Текстовый редактор отменяет отступ, и стек теперь содержит два элемента. Эта операция противоположна push и обычно называется pop.
Реализация стека Python
Есть несколько вариантов, как можно реализовать стек в Питоне. В этой статье мы рассмотрим не все из них, а только основные, которые удовлетворят почти все ваши потребности. Сосредоточимся на использовании структур данных, которые являются частью библиотеки Python, вместо того, чтобы писать свои собственные или использовать сторонние пакеты.
Изучим следующие реализации стека Python:
- list
- collections.deque
Использование списка для создания стека Python
Встроенная структура list, которую вы, вероятно, часто используете в своих программах, может быть использована в качестве стека. Вместо .push() вы можете использовать .append() для добавления новых элементов в верхнюю часть вашего стека, в то время как .pop() удаляет элементы в порядке LIFO:
>>> stack = []
>>> stack.append('а')
>>> stack.append('б')
>>> stack.append('в')
>>> stack
['а', 'б', 'в']
>>> stack.pop()
'в'
>>> stack.pop()
'б'
>>> stack.pop()
'а'
>>> stack.pop()
Traceback (most recent call last):
File "<console>", line 1, in <module>
IndexError: pop from empty listСписок вызовет ошибку IndexError, если вы вызовете .pop() в пустом стеке.
Преимущество списка в том, что он знаком почти всем. Вы знаете, как он работает, и, вероятно, уже использовали его в своих программах.
К сожалению, list имеет несколько недостатков по сравнению с другими структурами данных. Самая большая проблема заключается в том, что по мере роста он может столкнуться с проблемами скорости. Элементы в списке хранятся с целью обеспечения быстрого доступа к случайным элементам в списке. Это означает, что элементы хранятся рядом друг с другом в памяти.
Если ваш стек становится больше, чем блок памяти, который в данный момент его содержит, то Python необходимо выполнить некоторое распределение памяти. Это может привести к тому, что некоторые вызовы .append() будут занимать намного больше времени, чем другие.
Есть и менее серьезная проблема. Если вы используете insert() для добавления элемента в стек в позиции, отличной от конца, это может занять гораздо больше времени.
Следующая структура данных поможет вам обойти проблему перераспределения, с которой мы столкнулись в list.
Использование collections.deque для создания стека Python
Модуль collections содержит класс deque, который полезен для создания стеков Python. deque расшифровывается как “двусторонняя очередь”.
Вы можете использовать те же методы в deque, которые мы видели выше для list: append() и pop():
>>> from collections import deque
>>> stack = deque()
>>> stack.append('1')
>>> stack.append('2')
>>> stack.append('3')
>>> stack
deque(['1', '2', '3'])
>>> stack.pop()
'3'
>>> stack.pop()
'2'
>>> stack.pop()
'1'
>>> stack.pop()
Traceback (most recent call last):
File "<console>", line 1, in <module>
IndexError: pop from an empty dequeЭто выглядит почти идентично приведенному выше примеру списка. Вам может быть интересно, почему разработчики ядра Python создали две структуры данных, которые выглядят одинаково.
Зачем нужны deque и list?
Как вы видели выше, список построен на блоках непрерывной памяти, что означает, что элементы в списке хранятся рядом друг с другом:
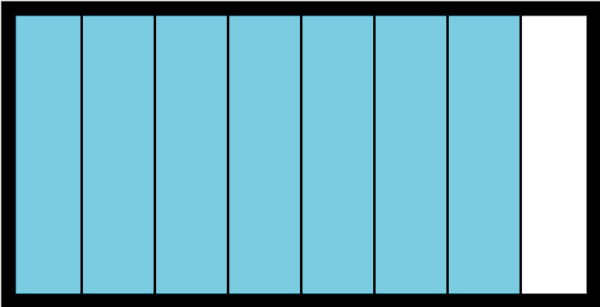
Это отлично работает для некоторых операций, таких как индексация в списке. Получение myList[5] происходит быстро, так как Пайтон точно знает, где искать элемент в памяти. Такое расположение также позволяет удобно и быстро работать со срезами в списках.
Расположение в непрерывной памяти является причиной того, что для вызова .append() некоторых объектов list может потребоваться больше времени, чем для других. Если блок непрерывной памяти заполнен, то нужно будет найти другой блок, что может занять гораздо больше времени:
Расположение в непрерывной памяти является причиной того, что для вызова .append() некоторых объектов list может потребоваться больше времени, чем для других. Если блок непрерывной памяти заполнен, то нужно будет найти другой блок, что может занять гораздо больше времени:
deque, с другой стороны, построен на основе двусвязного списка. В структуре связанного списка каждая запись хранится в своем собственном блоке памяти и имеет ссылку на следующую запись в списке.
Двусвязный список – это то же самое, за исключением того, что каждая запись имеет ссылки как на предыдущую, так и на следующую запись в списке. Это позволяет легко добавлять узлы в любой конец списка.
Для добавления новой записи в связанный список требуется только установить ссылку на новую запись так, чтобы она указывала на текущую вершину стека, а затем переместить вершину стека на новую запись:
Двусвязный список – это то же самое, за исключением того, что каждая запись имеет ссылки как на предыдущую, так и на следующую запись в списке. Это позволяет легко добавлять узлы в любой конец списка.
Для добавления новой записи в связанный список требуется только установить ссылку на новую запись так, чтобы она указывала на текущую вершину стека, а затем переместить вершину стека на новую запись:

Однако, добавление и удаление записей в стек в течение постоянного времени сопряжено с компромиссом. Получение myDeque[4] происходит медленнее, чем для списка, потому что Python должен пройти через каждый узел списка, чтобы добраться до четвертого элемента.
К счастью, вы редко будете выполнять случайную индексацию или срез в стеке. Большинство операций со стеком состоят либо из push, либо из pop.
Операции с константным временем выполнения append() и .pop() делают deque отличным выбором для реализации стека Python, если ваш код не использует многопоточность.
Стеки Python и многопоточность
Стеки Python также могут быть полезны в многопоточных программах.
Два варианта, которые вы видели до сих пор, list и deque, ведут себя по-разному, если в программе используются потоки.
Вы никогда не должны использовать list для какой-либо структуры данных, к которой могут получить доступ несколько потоков. Список не является потокобезопасным.
С deque немного сложнее. Если вы прочитаете документацию для deque, в ней четко указано, что обе операции .append() и .pop() являются атомарными, что означает, что они не будут прерваны другим потоком.
Поэтому, если вы ограничитесь использованием только .append() и .pop(), то код будет потокобезопасным.
Проблема с использованием deque в многопоточной среде заключается в том, что в этом классе есть другие методы, и они не предназначены для атомарного использования и не являются потокобезопасными.
Таким образом, хотя можно создать потокобезопасный стек Python с использованием deque, это подвергает вас риску того, что кто-то неправильно воспользуется им в будущем и вызовет состояние гонки (race conditions).